123 发布:2024-11-01 18:55 143
本文深入探讨强化学习的核心概念,包括其算法经典案例以及未来挑战强化学习旨在通过智能体与环境的交互,学习优化策略,以实现通用人工智能以马尔可夫决策过程MDP为基础,强化学习通过最大化环境奖励,不断调整行为策略强化学习算法关注长期奖励与即时反馈的平衡,涉及动作价值方法和基于梯度的决策;强化学习是一个在人工智能和机器学习中被广泛使用的概念强化学习的目标是让一个机器智能体能够在一个不断变化的环境中,通过尝试和错误来学习,最终达到优秀的决策结果强化学习中的三种强化方式是外部强化替代强化和自我强化外部强化和替代强化和自我强化外部强化外部强化是指强化学习机器智能体通过外;强化学习中注重以下几个方面1奖励函数设计强化学习的核心在于通过奖励信号来指导智能体学习2状态空间和动作空间的设计在强化学习中,状态空间和动作空间的设计对于智能体的学习效果也有很大的影响3策略搜索算法的选择在强化学习中,策略搜索算法是指智能体根据当前的状态和奖励信号,更新;强化学习是一种机器学习方法,与监督学习和非监督学习不同,强化学习是通过与环境的互动来学习决策和策略强化学习的目标是让智能体能够适应环境,并在环境中实现最大化累积奖励的目标强化学习的基本思想是通过反复地与环境进行交互,智能体不断地尝试不同的行为,并从环境中获得反馈和奖励,从而学习到;强化学习的基本要素如下1环境状态即Environment所描述对象的情况由于强化学习本身的设计,其状态可认为是离散的,或者简单来说,就是一步一步的具体的取值,取决于你的采样方式,更取决于你设计的算法本身的需求2Agent的动作这个取值也完全取决于你的需求与设计请大家务必记住这个序列;强化学习是指在某一种学习上不断巩固和完善,而对抗学习,更像是两个人摩拳擦掌此消彼长。

强化学习Reinforcement Learning, RL是一门让智能体通过与环境交互学习优化目标的学问核心在于智能体通过不断试错,通过即时奖励公式来调整策略,实现最大奖励的获取马尔科夫决策过程MDP是强化学习的基石,它结合了状态转移公式动作选择和奖励机制,其中每个状态s和动作a之间的关系;强化学习和监督学习的区别是定义不同强化学习简介强化学习Reinforcement Learning,RL,又称再励学习评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题监督学习简介监督学习是指利用一组已知类别的样。
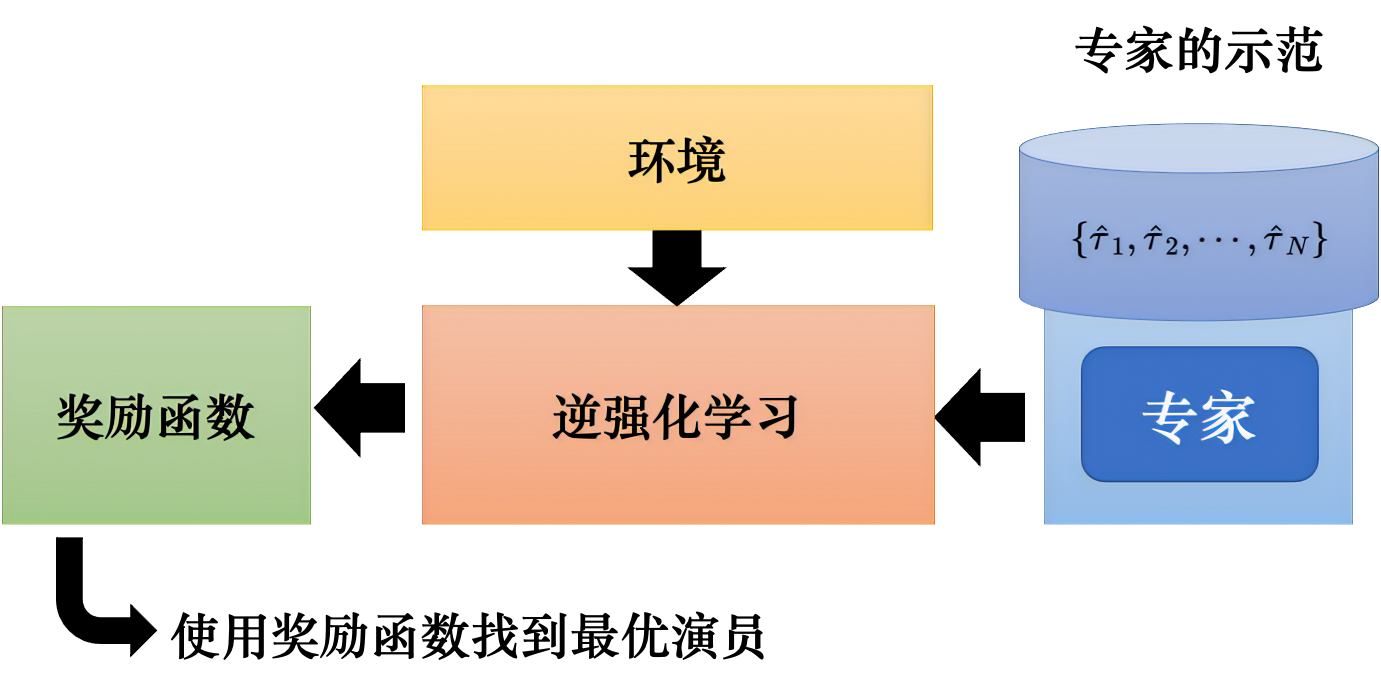
强化的四种类型分别是什么首先,从激励信号的分类方面来看,强化学习可以分为两种类型稀疏型和稠密型稀疏型激励信号在训练过程中仅在特定状态下才给予奖励信号,因此智能体需要花费较长时间才能找到最优解或决策然而,对于稠密型激励信号,每个状态都会得到奖励,因此智能体可以更快地找到最优解或决策;强化学习和深度学习是两种技术,只不过深度学习技术可以用到强化学习上,这个就叫深度强化学习1强化学习其实也是机器学习的一个分支,但是它与我们常见的机器学习不太一样它讲究在一系列的情景之下,通过多步恰当的决策来达到一个目标,是一种序列多步决策的问题强化学习是一种标记延迟的监督学习2;强化学习理论是一种机器学习方法,旨在让计算机代理使用尝试和错误的方法,通过与环境互动来学习决策制定和行为选择它着重于如何使代理能够采取最优行动,以获得最大的奖励强化学习理论的教学意义主要包括以下几个方面1 让学生了解基本的强化学习原理和算法,以及如何将其应用于不同领域的问题中2;自从人工智能这一事物流行以后,也开始流行了很多的新兴技术,比如机器学习深度学习强化学习增强学习等等,这些技术都在人工智能中占据着很大的地位我们在这篇文章中重点给大家介绍一下关于强化学习需要了解的知识,希望这篇文章能够更好地帮助大家理解强化学习为什么强化学习是一个热门的研究课题呢;强化学习Reinforcement Learning, RL又称为增强学习评价学习等,和深度学习一样是机器学习的一种范式和方法论之一,智能体从一系列随机的操作开始,与环境进行交互,不断尝试并从错误中进行学习策略,最大化回报值,最终找到规律实现既定目标强化学习的过程智能体首先采取一个与环境进行交互的动作。
以下是四种常见的强化学习机制其原理1 正向强化机制Positive Reinforcement当智能体执行一个动作后,如果得到正向的奖励或反馈它会向于增加这个作的率这种机制基于奖励的强化,通过增加奖励来鼓励智能体执行积极的行为,帮助智能体通过最优的策略这种机制类于人类受到奖励后的积反馈效应2向强化;强化学习描述的是智能体在环境中尝试各种动作,通过获取反馈不断调整动作以完成任务的过程在这一过程中,智能体与环境交互,形成一系列概念随机性在强化学习中来源于策略函数与状态转移函数动作具有随机性,由智能体在给定状态下通过概率采样生成状态转移也具有随机性,环境在给定状态和动作时会生成新;强化学习通常具有延迟奖励序列决策以及与环境交互等特点1延迟奖励 与监督学习和无监督学习不同,强化学习不是立即给予奖励或惩罚,而是根据整个序列的累积奖励来决定学习效果这种延迟奖励机制使得强化学习更加适应于具有长期依赖性的复杂任务2序列决策 强化学习通常需要解决的是序列决策问题,即在。
版权说明:如非注明,本站文章均为 小宅猫 原创,转载请注明出处和附带本文链接;