123 发布:2024-10-24 03:05 146
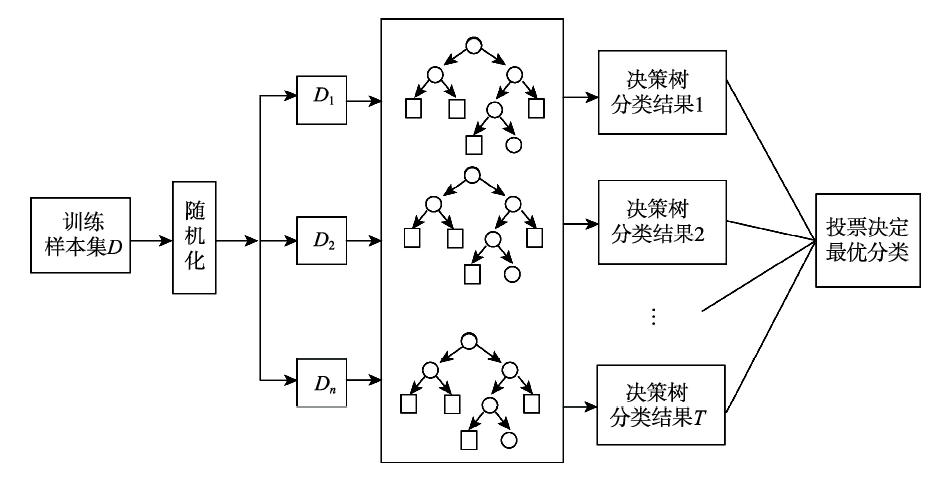
1、随机森林随机森林通俗理解是随机森林分解开来就是“随机”和“森林”“随机”的含义我们之后讲,我们先说“森林”,森林是由很多棵树组成的,因此随机森林的结果是依赖于多棵决策树的结果这是一种集成学习的思想随机森林是一种集成算法EnsembleLearning,它属于Bagging类型,通过组合多个弱分类器。
2、随机森林 1对于很多种资料,可以产生高准确度的分类器2可以处理大量的输入变数3可以在决定类别时,评估变数的重要4在建造森林时,可以在内部对于一般化后的误差产生不偏差的估计5包含一个好方法可以估计遗失的资料,并且,如果有很大一部分的资料遗失,仍可以维持准确度6提供一个。
3、R中的RF指的是随机森林随机森林是一种监督学习算法,主要应用于分类和回归任务以下是关于随机森林的详细解释1 随机森林的基本构成随机森林是由多个决策树组成的分类器集合每一棵决策树都是独立训练得到的,并且最终的分类或预测结果是通过多数投票或平均的方式得到的这种集成方法能够显著提高模。
4、树模型决策树随机森林与提升回归树的概述树模型作为一种强大的机器学习工具,主要包括决策树Decision Tree, DT随机森林Random Forest, RF以及提升回归树Boosting Regression Tree, BRT分类树的核心是CART算法,它通过计算GG#39值来确定最优分割点,GG#39值越大,表示分割效果越好,有。
5、1随机森林优点 对于高维特征很多稠密型的数据适用,不用降维,无需做特征选择 构建随机森林模型的过程,亦可帮助判断特征的重要程度 可以借助模型构建组合特征 并行集成,有效控制过拟合 工程实现并行简单,训练速度快 对于不平衡的数据集友好,可以平衡误差 对于特征确实鲁棒性强,可以。
6、机器学习算法详解随机森林AdaBoostGBDTXGBoost理解机器学习中的随机森林AdaBoostGBDT和XGBoost算法,可以从它们的基本概念和实际应用出发1 信息熵与条件熵信息熵衡量不确定性,公式为公式条件熵则是给定Y后X的不确定性,公式为公式2 信息增益与基尼指数信息增益表示不确定性。
7、随机森林是一种高效实用的机器学习算法,其核心在于将多个决策树集成起来,形成quot森林quot,从而达到提高模型精度和鲁棒性的目的随机森林算法的quot随机quot特性体现在两方面一是通过有放回抽样,从原始数据集中生成多个独立的训练集二是对每个训练集构建决策树时,随机选择特征和样本进行训练决策树是用于分类。
8、随机森林是为了解决决策树的过拟合问题而设计的它通过Bootstrap方法生成样本集,使用bagging策略集成多个决策树,同时在样本随机和特征随机的基础上构建随机森林随机森林的定义是在利用bagging策略生成决策树的过程中,满足样本随机和特征随机的决策树群在构建随机森林时,可以使用Bootstrap方法生成多个大小。
9、因果推断作为计量经济学的核心问题,近年来开始注重对个体处理效应的估计Athey和Imbens在去年JASA的文章中提出,基于决策树和随机森林的方法,即因果森林,解决了个体处理效应估计的异质性问题这种方法提供了一个非参数解决方案,避免了传统非参数方法在变量维度增加时效果下降的问题决策树是机器学习中常用。
10、此外,通过Brier score评估方法,我们能更精确地量化模型预测的准确性,并随时间变化呈现优化节点参数有助于提高模型性能,如在本文中,最佳节点数被设定为10随机森林还提供了变量重要性评估,通过部分依赖图PDP,我们深入探究了年龄age和Karnofsky评分karno对生存率的具体影响如果你对R。
11、微生物随机森林既可以用作分类,也可以用于回归根据查询CSDN博客得知,微生物随机森林分类的原理是,在得到森林之后,当有一个新的输入样本进入的时候,让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类,然后看看哪一类被选择最多,就然后选择一个变量,这个变量使得通过这个进行分类。
12、决策树随机森林GBDTLightGBM和XGBoost都是常见的机器学习算法,它们各自拥有一系列重要的参数,以控制模型的性能和复杂度以下是它们的关键参数和调整策略概述1 决策树模型DecisionTreeClassifier的超参数包括可能影响模型复杂度和过拟合的参数,如树的最大深度和最小叶子节点样本数2 随机。
13、1随机森林指的是利用多棵树对样本进行训练并预测的一种分类器该分类器最早由LeoBreiman和AdeleCutler提出,并被注册成了商标21随机森林在解决回归问题时,并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续的输出当进行回归时,随机森林不能够作出超越训练集数据范围的预测。
14、定义不同,模型类型不同1定义不同随机森林是用于分类和回归的监督式集成学习模型逻辑回归是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域2模型类型不同逻辑回归是一种二分类模型而随机森林是一种多分类模型。
15、随机森林算法是基于决策树的集成学习算法,其核心思想是将多个决策树集合起来,以求取最优解随机森林的原理是先在每个决策树中随机选择特征特征值对数据进行划分,然后每棵决策树给出预测结果,最后通过投票结果确定最终的预测结果优点是算法稳定,预测准确,而且可以处理缺失值,计算结果可解释性强。
16、不能随机森林可以预测的最大案例数是训练数据集中的最大案例数,因此没办法预测增长变化中的未来值随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。
17、而0,1,2J为标准,建议事件可以不连续编码,但必须始终使用0进行审查将拆分规则设置为logrankscore将导致生存分析,其中所有事件都被视为相同类型通常,竞争风险需要比生存设置更大的节点大小RandomForestSRC 是美国迈阿密大学的科学家 Hemant Ishwaran和 Udaya B Kogalur开发的随机森林算法,它。
版权说明:如非注明,本站文章均为 小宅猫 原创,转载请注明出处和附带本文链接;